
Recently, I was looking for a way to easily scrape data from websites. In fact, as we all know, manually scraping the web can turn into a tedious and time-consuming task. While searching online for smarter solutions to avoid these downsides, I came across Octoparse.
Octoparse is a web scraping service that allows you to extract data from multiple websites with no code involvement. As a consequence, anyone can use this no-code tool. Follow this link if you want to learn more about web scraping.
Moreover, it provides official APIs to execute previously-defined scraping tasks on-demand and save the extracted data in CSV, TXT, Excel, HTML, or to databases. This way, you can have the benefits of both a no-code tool and an advanced manual tool.
Let’s see how to use Octoparse to create a scraping task, execute it from a Python script, and save the extracted data in a Google Sheets document.
What Is Octoparse?
“Octoparse is an extremely powerful data extraction tool that has optimized and pushed our data scraping efforts to the next level” — Octoparse official website
Octoparse is a robust website crawler aimed at extracting every kind of data you need from the web. It offers a large set of features, including auto-detection, task templates, and an advanced mode.
The first one is based on an auto-detection algorithm designed to automatically scrape pages containing items nested in a list or a table. The second one is a simple way to scrape data based on a number of pre-built templates employable from anyone with no effort. While the third one is a flexible and powerful mode designed for those requiring more custom needs.
In each case, Octoparse involves a user-friendly point-and-click interface conceived to guide you throughout the data extraction process. Then, data extracted from multiple websites can be easily saved and structured in many formats.
Plus, it provides a scheduled cloud extraction feature to extract dynamic data in real-time. Then, it comes also with an API program, which I will show you how to use shortly.
Furthermore, although the tool reproduces human activity to communicate with web pages and avoid being detected while scraping, it offers IP proxy servers as well. They can be used in case of aggressive websites to hide IP and avoid IP blocking.
In conclusion, Octoparse satisfies most of the users’ scraping needs, both basic or advanced, not requiring any coding skills.
Creating a Data Extraction Task
Let’s say we want to scrape data from the List_of_countries_and_dependencies_by_population Wikipedia page. This is a good example of a webpage whose data is updated frequently over time.
First, we will see how to install Octoparse. Then we will define a scraping task aimed at extracting data from the main table of that webpage.
1. Getting started with Octoparse
First of all, you need to install Octoparse. In this tutorial, I am going to use Octoparse 8.x, which can be downloaded from here: https://www.octoparse.com/download.
Then, follow the next few steps:
- Unzip the downloaded installer file
- Run the OctoparseSetup.msi file
- Follow the installation instructions
- Log in with your Octoparse account, or sign up here if you do not have an account yet.
Please, note that signing up is free, but in order to access the API feature, a Standard Plan is required. You can find all the information on the plans offered by Octoparse here.
Now, you have everything required to start harnessing the power of Octoparse.
2. Creating the Task
Since the goal is to extract data stored in a table, following this guide from the official documentation on how to achieve so is highly recommended.
Launch Octoparse, login, enter your desired URL in the main field and click the Start button. This way, the system is going to use the auto-detection algorithm, which is perfect for a page made up of a table such as: https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_population .
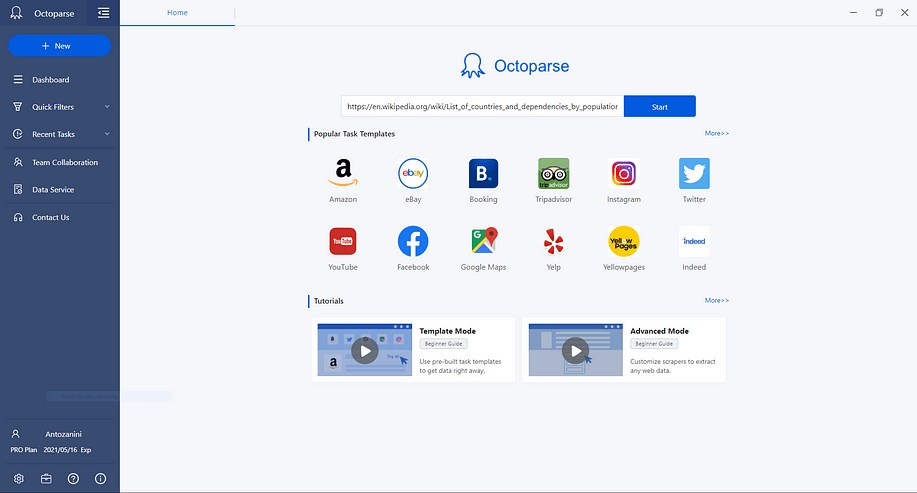
Wait for the page to be loaded and data to be detected. When the auto-detection completes, follow the instruction provided on the Tips panel and check your data in the preview section. Finally, rename the data fields or remove those that you do not need.
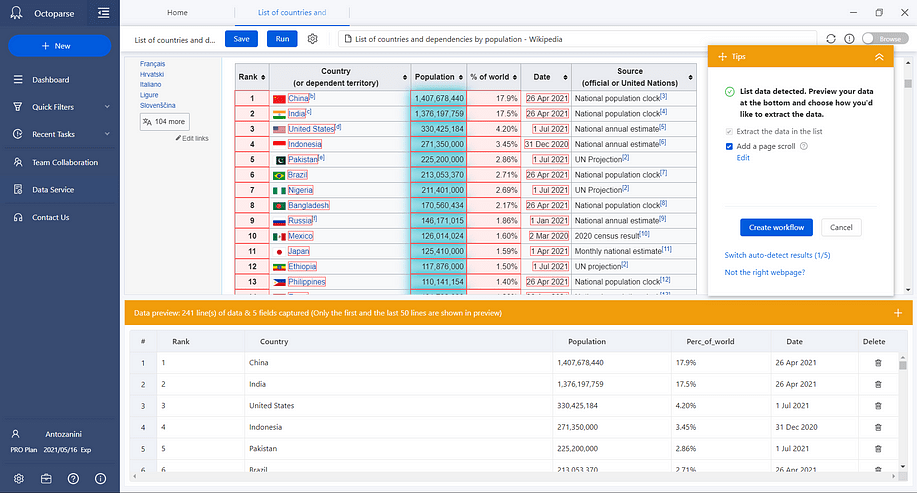
First, click on the Create workflow button from the Tips panel. Second, click on the Save button in the top bar. Then, go to the Dashboard view and you should see the task you just defined as in the picture below:
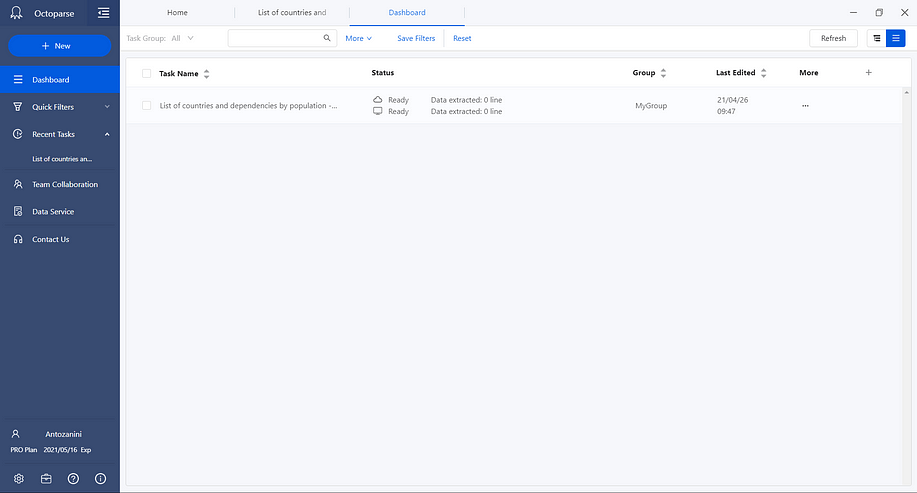
Here you can rename your tasks and execute them locally or in the cloud. Mission complete! You are now ready to access the extracted data. The tutorial could end now, but if you want to run this task via API, you need to click on the API option from the More > Cloud runs menu.
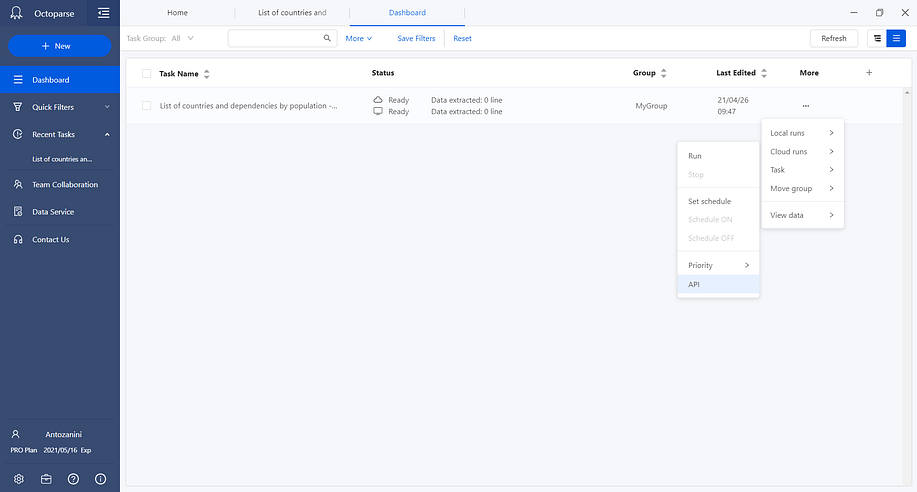
Then, another window presenting your Task ID will appear. You will need it later, so remember to save it in a safe place.
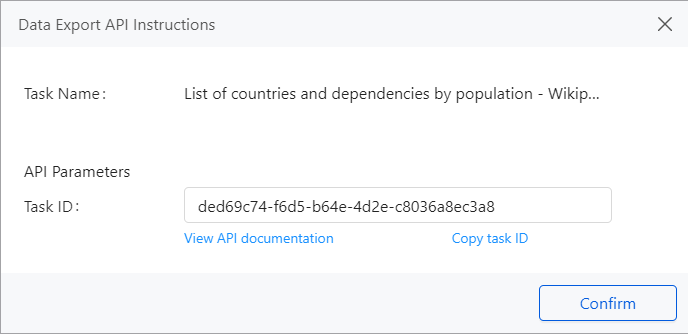
Programmatically Running the Task with Python
Now, it is time to delve into how to use Octoparse APIs to create a script aimed at programmatically running the task previously defined and save the extracted data in a Google Sheets document.
Please, note that as stated in the official documentation, this last goal can be achieved only via API only. In particular, you can accomplish this with the following Python script:
import sys
import requests
import os
import gspread
import pandas as pd
def login(base_url, email, password):
"""login and get a access token
Arguments:
base_url {string} -- authrization base url(currently same with api)
email {[type]} -- your email
password {[type]} -- your password
Returns:
json -- token entity include expiration and refresh token info like:
{
"access_token": "ABCD1234", # Access permission
"token_type": "bearer", # Token type
"expires_in": 86399, # Access Token Expiration time (in seconds)
"refresh_token": "refresh_token" # To refresh Access Token
}
"""
content = 'username={0}&password={1}&grant_type=password'.format(email, password)
token_entity = requests.post(base_url + 'token', data=content).json()
if 'access_token' in token_entity:
return token_entity
else:
os._exit(-2)
def get_data_by_offset(base_url, token, task_id, offset=0, size=10):
"""offset, size and task ID are all required in the request.
Offset should default to 0, and size∈[1,1000] for making the initial request.
The offset returned (could be any value greater than 0) should be used for making the next request.
Arguments:
base_url {string} -- base url of the api
token {string} -- token string from a valid token entity
task_id {string} -- task id of a task from our platform
Keyword Arguments:
offset {int} -- an offset from last data request, should remains 0 if is the first request (default: {0})
size {int} -- data row size for the request (default: {10})
Returns:
json -- task dataList and relevant information:
{
"data": {
"offset": 4,
"total": 100000,
"restTotal": 99996,
"dataList": [
{
"state": "Texas",
"city": "Plano"
},
{
"state": "Texas",
"city": "Houston"
},
...
]
},
"error": "success",
"error_Description": "Action Success"
}
"""
url = 'api/allData/getDataOfTaskByOffset?taskId=%s&offset=%s&size=%s' % (task_id, offset, size)
task_data_result = requests.get(base_url + url, headers={'Authorization': 'bearer ' + token}).json()
return task_data_result
def run_countries_task(base_url, token_entity):
"""Running the countries task
Arguments:
base_url {string} -- API base url
token_entity {json} -- token entity after logged in
"""
# retrieving an access token after the login
token = token_entity['access_token']
# your task id
task_id = "ded69c74-f6d5-b64e-4d2e-c8036a8ec3a8"
# running the task and retrieving data
data = get_data_by_offset(base_url, token, task_id, offset=0, size=1000)
# retrieving the extracted data in JSON format
json_extracted_data = data['data']['dataList']
# converting the JSON string to CSV
df = pd.DataFrame(json_extracted_data)
csv_extracted_data = df.to_csv(header=True).encode('utf-8')
# check how to get "credentials":
# https://gspread.readthedocs.io/en/latest/oauth2.html#for-bots-using-service-account
# credentials = ... your credentials
gc = gspread.service_account_from_dict(credentials)
# spreadsheet_id = ... -> your spreadsheet_id
# importing CSV data into your Google Sheet document identified
# by spreadsheet_id
gc.import_csv(spreadsheet_id, csv_extracted_data)
if __name__ == '__main__':
# the email you used to subscribe to Octoparse
email = "test@email.com"
# your password
password = "password"
octoparse_base_url = 'http://advancedapi.octoparse.com/'
token_entity = login(octoparse_base_url, email, password)
run_countries_task(octoparse_base_url, token_entity)First, the login is performed, then the Get Data By Offset API is called to launch the desired task and retrieve the extracted data in JSON format. This data is converted into CSV format and finally imported into a Google Sheets document using the gspread library.
After executing the script, you will be able to see the data extracted by the Octoparse task saved in your selected Google Sheets document as follows:
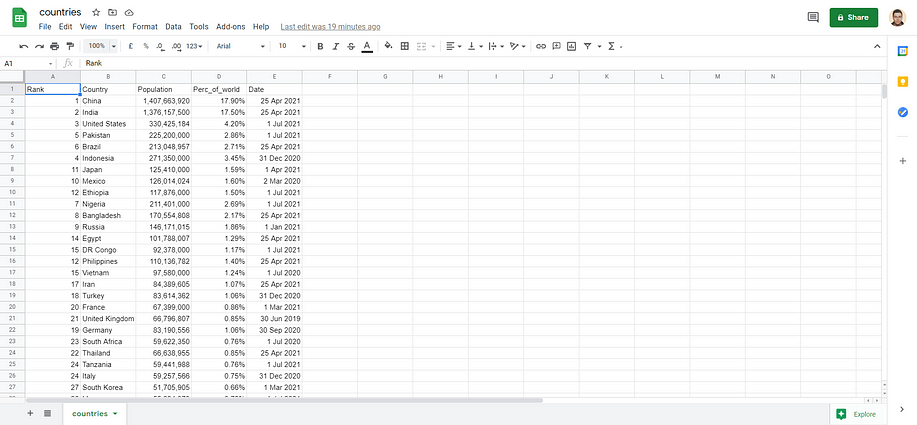
Et voilà! Goal achieved with just a few lines of code.
Conclusion
In this article, we looked at how to use Octoparse, a powerful data extraction tool, to easily create a scraping task. Then, we saw how such a task can be integrated into a Python script to be run programmatically and save the extracted data in a Google Sheets document. As shown, this is possible thanks to the official Octoparse API program, which turns Octoparse into a no-code but highly advanced tool.
Thanks for reading! I hope that you found this article helpful.
