
In this article, you will learn how partitioning your database taking into account the semantics behind your data can drastically improve your application’s performance. Mainly, you will learn that you should tailor the partitioning criteria to your unique application domain. Such an approach can be a game-changer when it comes to performance, as you are about to see through a real-world scenario based on a data-driven backend application developed for a startup operating in the sports industry.
Let’s now delve into this scenario and learn why cannot ignore your data context when you have to partition a database.
Presenting the Context
For the past few years, I have been collaborating with a European startup to develop a sophisticated web application aimed at providing sports experts with advanced features to make decisions and explore data. This application offers both raw and aggregated data, although the professionals who adopted it prefer the latter. The underlying database contains terabytes of complex, unstructured heterogeneous data coming from several providers. So, the biggest challenge was trying to design a reliable, fast, and easy-to-explore database. Now, let’s delve deeper into the scenario.
Application domain
The web application supports any kind of sport. On the other hand, the startup I collaborate with is based in Europe – and Europeans love soccer. So, it has been adopted mainly by soccer coaches, experts, and professional players. In this industry, there are many providers available that offer their clients access to the events of the most important games. In detail, they provide you with data related to what happened during a game, such as goals, assists, yellow cards, passes, and much more. Each of the hundreds of games played daily in the world typically comes with thousands of rows. So, the table containing this data is by far the largest one.
VPS specs, technologies, and architecture
My team has been in charge of developing the backend application providing the most crucial data exploration features. We adopted Kotlin v1.6 running on top of a JVM (Java Virtual Machine) as the programming language, Spring Boot 2.5.3 as the framework, and Hibernate 5.4.32.Final as the ORM (Object Relational Mapping). The main reason why we opted for this technology stack is that speed is one of the most crucial business requirements. So, we needed a technology that could leverage heavy multi-thread processing, and Spring Boot turned out to be a reliable solution.
We deployed our backend on a 16GB 8CPU VPS through a Docker container managed by Dokku. It can use 15GB of RAM at most. This is because one GB of RAM is dedicated to a Redis-based caching system. We added it to improve the performance and avoid overloading the backend with repeated operations.
Database and table structure
As for the database, we decided to opt for MySQL 8. An 8GB and 2 CPU VPS currently hosts the database server, which supports up to 200 concurrent connections. The backend application and the database are in the same server farm to avoid communication overhead. We designed the database structure to avoid duplication and with performance in mind. We decided to adopt a relational database because we wanted to have a consistent structure to convert the data received from the providers into. This way, we are standardizing the sports data, making it easier to explore and present it to the end-users.
At the time of writing, the database contains hundreds of tables, and I cannot present them all because of the NDA I signed. Luckily, one table is enough to analyze completely why we ended up adopting the data context-based partition you are about to see. This is because the real challenge came when we started to perform heavy queries on the Events table. But before diving into that, let’s see what the Events table looks like:
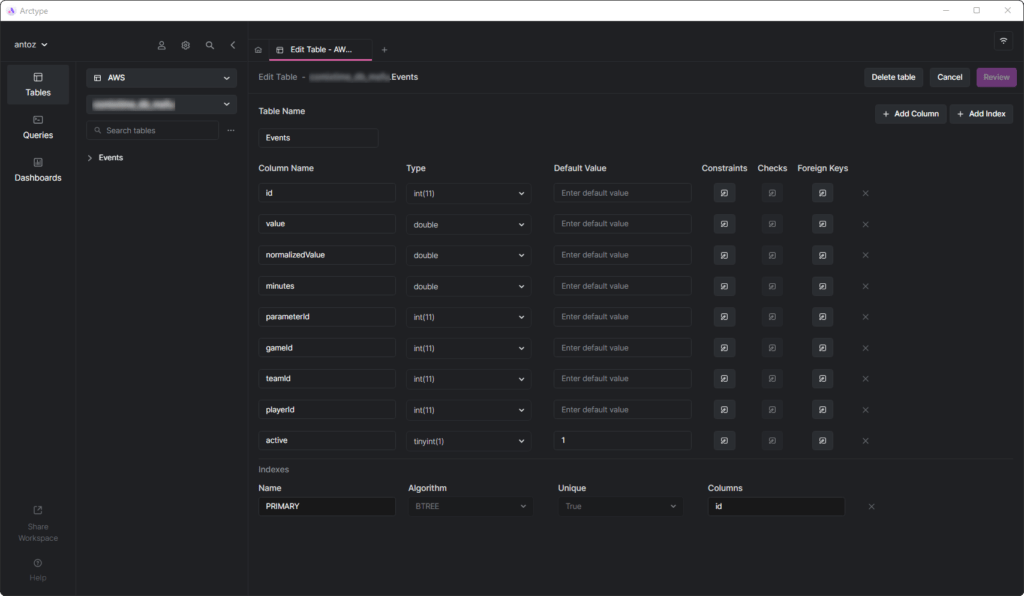
Events tableAs you can see, it does not involve many columns, but keep in mind that I had to omit some of them for confidentiality reasons. But what really matters here are the parameterId and gameId columns. We use these two foreign keys to select a type of parameter (e.g., goal, yellow card, pass, penalty) and the games in which it happened.
Performance issues
In a just few months, the Events table reached half a billion rows. As we have already covered in depth in this blog post, the main problem is that we need to perform aggregate operations using slow IN queries. This is because what happens during a game is not so important. Instead, sports experts want to analyze aggregated data to find trends and make decisions based on them.
Also, although they generally analyze the entire season or the last 5 or 10 games, they also want to be able to exclude some particular games from their analysis. This is because they do not want a game played particularly poorly or well to polarize their results. But we cannot pre-generate the aggregate data, because we would have to do this on all possible combinations, which is not feasible. So, we have to store the entire data and aggregate it on the fly.
Understanding the Performance Problem
Now, let’s delve into the main aspect that led to the performance issues we had to face.
Million-row tables are slow
If you have ever dealt with tables containing hundreds of millions of rows, you know that they are inherently slow. Clearly, you cannot even think of running JOINs on such large tables. Yet, you can perform SELECT queries in a reasonable amount of time. This is particularly true when these queries involve simple WHERE conditions. On the other hand, when using aggregate functions or IN clauses, they become terribly slow. In these cases, they can easily take up to 80 seconds, which is simply too much.
Indexes are not enough
To improve the performance, we decided to define some indexes. This was our first approach to trying to find a solution to the performance issues. Unfortunately, this led to another problem. Indexes take time and space. This is generally insignificant, but not when you are dealing with such large tables. It turned out that defining complex indexes based on the most common queries took several hours of time and GBs of space. Also, indexes are helpful but are not magic.
Data Context-Based Database Partitioning as a Solution
Since we could not solve the performance problem with custom-defined indexes, we decided to try a new approach. We talked with other experts, looked online for solutions, read articles based on similar scenarios, and finally decided that partitioning the database was the right approach to follow.
Why traditional partitioning may not be the right approach
Before partitioning all our largest tables, we spent some time studying the topic both on the MySQL official documentation and interesting articles. Although we all agreed that this was definitely the way to go, we also realized that applying partitioning without taking our particular application domain into account would be a mistake. Specifically, we understood how crucial it is to find the right criteria when partitioning a database. Luckily, analyzing our tables, we were unable to extract efficient criteria.
Some experts in partitioning taught us that the traditional approach is to partition on the number of rows. But we wanted to find something smarter and more efficient than that.
Delving into the application domain to find the partitioning criteria
By analyzing the application domain and interviewing our users, we understood an essential lesson. Sports experts tend to analyze aggregated data on games of the same competition. This means that they take into account data coming from different competitions very rarely. Also, they prefer to explore data season by season. In other words, they seldom leave the context represented by a sports competition played in a particular season. In our database structure, we represented this concept with a table called SeasonCompetition, whose goal is to associate a competition with a certain season. So, we realized that a good approach would be to partition our larger tables into sub-tables related to a particular SeasonCompetition instance.
Specifically, we defined the following name format for these new tables:
<tableName>_<seasonCompetitionId>Consequently, if we had 100 rows in the SeasonCompetition table, we would have to split the large Events table into the smaller Events_1, Events_2, …, Events_100 tables. Based on our analysis, this approach would lead to a huge performance boost in the average case, although introducing some overhead in the rarest cases.
Matching the criteria with the most common queries
Before coding and launching the scripts to execute this complex and potentially returnless operation, we validated our studies by looking at the most common queries performed by our backend application. But by doing so, we found out that the vast majority of queries involved only games played within a SeasonCompetition. This convinced us that we were right. So we ended up partitioning all the large tables in the database with the approach just defined.
AVG query in a database clientNow, let’s study the pros and cons of this decision.
Pros
- Running queries on a table containing at most 1/2 million rows is much more performant than doing it on a table of half a billion rows, especially when it comes to aggregate queries.
- Smaller tables are easier to manage and update. Adding a column or index is not even comparable to before in terms of time and space. Plus, each SeasonCompetition is different and requires different analyses. Consequently, it may require special columns and indexes and the aforementioned partitioning allows us to deal with this easily.
- The provider might amend some data. This forces us to perform delete and/or update queries, which are infinitely faster on such small tables. Plus, they always involve only some games of a particular
SeasonCompetition, so we only need to operate only on a single table now.
Cons
- Before making a query on these sub-tables, we need to know the seasonCompetitionId associated with the games of interest. This is because the seasonCompetitionId value is used in the table name. Therefore, our backend needs to retrieve this info before running the query by looking at the games in analysis, and this represents a small overhead.
- When a query involves a set of games that regard many SeasonCompetition, the backend application must take care of running a query on each sub-table. So, in these cases, we can no longer aggregate the data at the database level, but we must do it at the application level. This introduces some complexity in the backend logic. At the same time, we can execute these queries in parallel. Also, we can aggregate the retrieved data efficiently and in parallel.
- Managing a database with thousands of tables is not easy and can be challenging to explore with a client. Similarly, adding a new column or updating an existing column in each table is cumbersome and requires a custom script.
Effects of the Data Context-Based Partitioning on the Performance
Let’s now look at the improvement achieved in terms of time when executing a query in the new partitioned database.
- Time improvement in the average case (query involving only one SeasonCompetition): from 20x to 40x
- Time improvement in the general case (query involving one or more SeasonCompetitions): from 5x to 10x
Final Thoughts
Partitioning your database is undoubtedly a good way to improve performance, especially on large databases. However, doing it without taking an account your particular application domain might be a mistake or lead to an inefficient solution. Instead, taking your time to study the domain by interviewing experts, your users, and looking at the most executed queries is crucial to conceiving highly efficient partitioning criteria. Here, we learned how to do this and the results of such an approach through a real-world case study.
