
Scraping web pages is one of the most effective ways to retrieve data from the web. On the other hand, every web page is different. So, extracting data from the Web programmatically requires a scraping script that involves custom logic.
Building such a script costs you time and money. Luckily, many scraping services that allow you to scrape the web with just a bunch of clicks have been recently developed. Thus, you no longer have to write code to achieve your data extraction goals!
Here, you will learn how to extract data from a media article with Listly, a scraping service that contacted me to test their product and review it honestly. Let’s jump into the article!
What Data to Scrape Media Articles and Why
A media article generally consists of:
- A title
- An optional TL;DR (Too Long; Didn’t Read) section
- One or more subtitles
- A list of paragraphs
- Some images
Not surprisingly, the most important information here is the text of the article, but also images and videos are important. In particular, when dealing with multimedia files, you have to take into account that they might be protected by copyright. And if you want to avoid problems, you might be asked to indicate where the multimedia file comes from. So, retrieving the information about the source and author of an image or a video is crucially important.
Then, you can use all this info to create a news aggregator app, add a news section to your website or app, study how a media article may change over time for marketing purposes, create a data source for your machine learning algorithm to study how language works, or simply share the article with your friends.
Now, let’s delve into the tool chosen to scrape data from media articles.
What Is Listly?
“Listly is a Web Scraping Service for everyone from non-technical marketers to advanced developers. It turns web pages into an Excel spreadsheet within seconds. The extracted data is used for retail, research, big data, and other data-related works.” — FAQ — Listly.io
The recommended way to use Listly is through the official Chrome extension, which has already been downloaded by more than 60k users.
Let’s not waste any more time and learn how to use Listly to scrape data from media articles.
Scraping Articles From CNN With Listly
Tiem to learn how to scrape data from media articles with Listly in a step-by-step tutorial with images.
1. Getting started with Listly
First, you need a Listly account. Visit this page, fill out the form, and click on “SIGN UP”.
You will receive the following email in your inbox to verify your email address:

Click on “Verify email” and you should now have a valid Listly account.
Next, you need to install the Listly Chrome extension. All you have to do is visit the Listly website and click on “ADD TO CHROME”.
Keep in mind that you can test Listly for free, but the free plan comes with some limitations. This means that if you want a complete experience, you need a paid plan.
Now, you have everything you need to start to scrape data from websites. But before starting using it, I recommend pinning Listly in the Chrome extension toolbar by clicking the following button:
2. Selecting the article to scrape
Now, visit a media website and choose the article you want to scrape. In this tutorial, you will see how to scrape the “Why Italy’s ‘king of chocolate’ is so delicious” article from the CNN website.
This is what the article looks like:
As you can see, it is a long and detailed article with several images. The main challenge with scraping media articles is that they generally consist of several blocks of text. Also, there might many ads, images, and embeds between them. So, developing a scraping script to retrieve the data you are interested in can involve complex logic. But you can avoid all this with Listly!
Now, let’s see how Listly allows you to scrape such a page with just a bunch of clicks and no code.
3. Scraping a CNN article with Listly in a few clicks
Visit the page of the article you selected and click on the Listly icon in the Chrome extension toolbar.
This is what the popup window displayed from the Listly extension looks like:
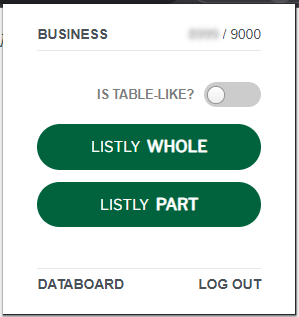
Since a media article is not table-like and you want to scrape the entire article, click on “LISTLY WHOLE”.
Wait for Listly to do its magic, and you should be redirected to the page below:
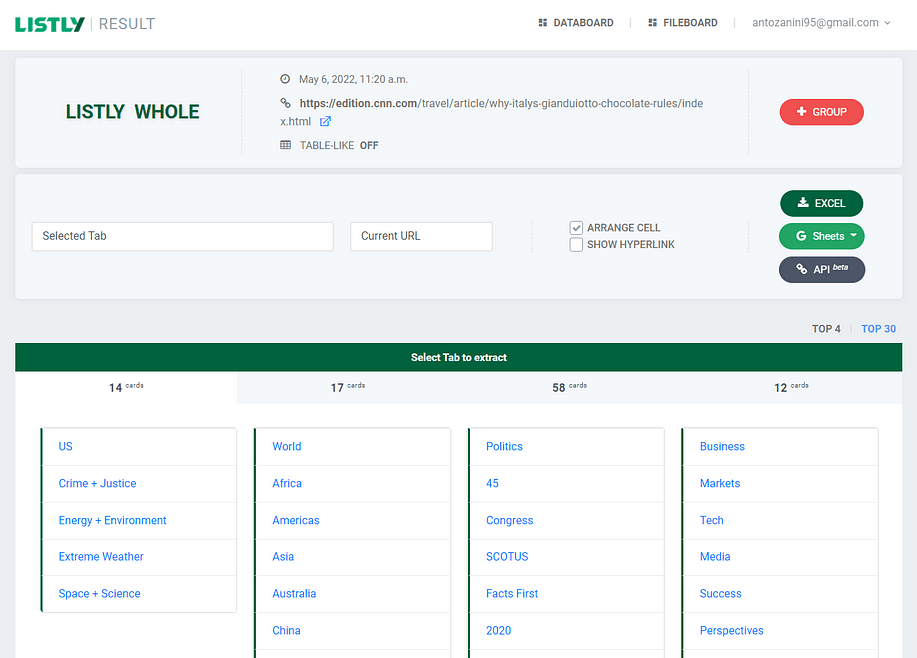
This is the Databoard page, where you can decide what data to scrape and what to ignore. Notice how Listly automatically scrapes and organizes for you all the cards found on the source webpage.
By exploring the data the Listly interface offers you, you should notice that the tab with 58 cards is the one containing what you are looking for. But only some of all the 58 cards are actually interesting. To select only the relevant ones, choose “Select Tabs” in the “Selected Cards” input field.
This is what your Listly Databoard page should now look like:
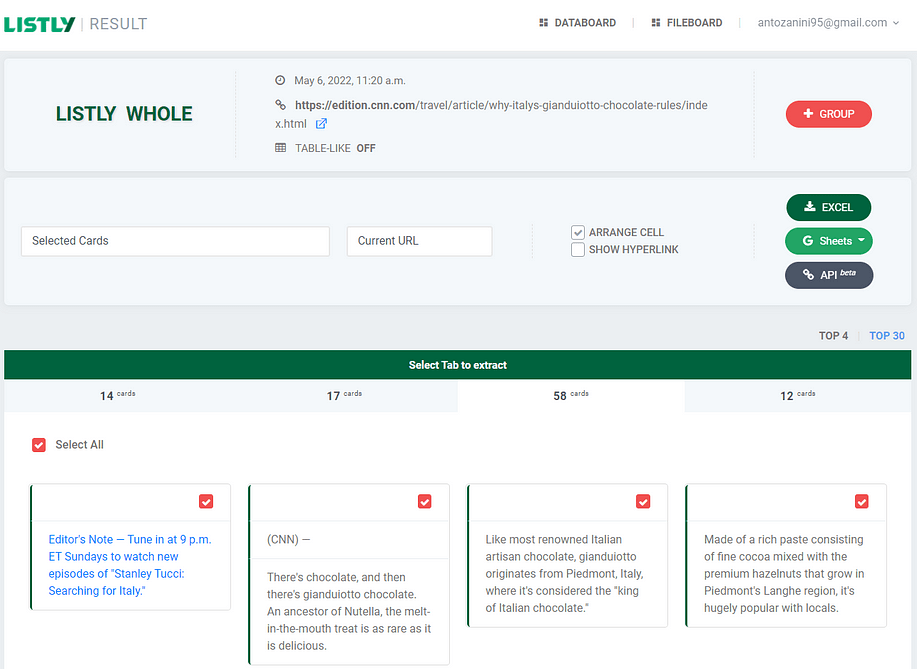
Now, each card has a check radio button you can use to select or deselect it. Only the card you marked as selected will be taken into account in the final data extraction process.
After selecting the cards of interest, click on the “EXCEL” button to export the extracted data into an Excel file. A LISTLY_SINGLE_XXXXXX_YYYYY.xlsx file will be automatically downloaded.
Open the Excel file, and you should see the data scraped from the CNN article that you manually selected organized in cells as in the image below:
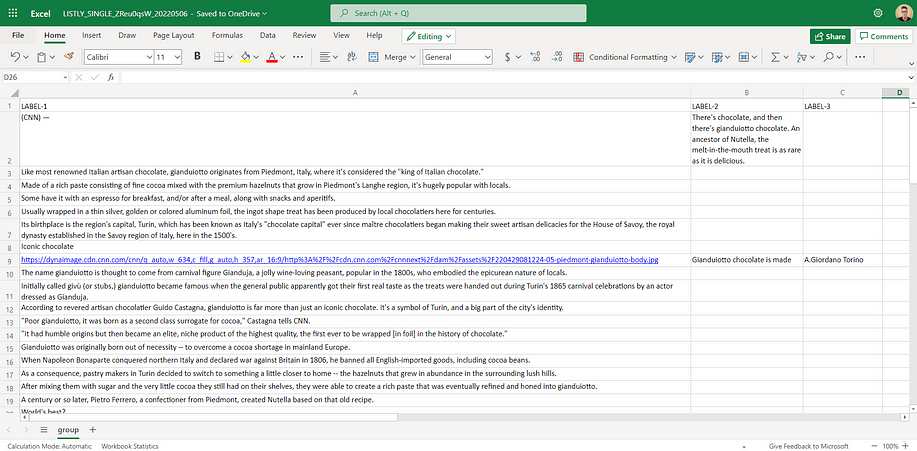
As you can see, the LABEL-1 column contains all the paragraphs, image URLs, and subtitles. The LABEL-2 column stores the TD;DR section and image captions. While the LABEL-3 column has the image author and copyright information.
Basically, in these three columns, there are all the most important data you can retrieve from a media article.
Et voilà! With just a few clicks, you can scrape a web page containing heterogeneous and structured content. All this, without writing a single line of code.
Listly: An Honest Review
Since it was Listly that contacted me to test out their product, I feel compelled to share with you my honest thoughts on it. The overall experience was definitely positive, but let’s now dive into the most relevant pros and cons based on my experience with Listly so far.
Pros
- Easy to use: The Listly UI is intuitive and guides you through the data extraction process.
- Fast: Scraping data from the media article took only a few seconds.
- Full of features: Listly equips you with the ability to schedule a daily extraction, get e-mail notifications, export multiple pages into an Excel spreadsheet on the Databoard page, upload .html files to Fileboard page, reproduce mouse/keyboard actions to load more data, repeat click to load more data, repeat scroll to load more data, auto-save while scrolling, select proxy server to change IP address, detect iframes, extract data from iframes, extract hyperlinks over content, and more.
Cons
- Spreadsheet exports only: At the time of writing, you can only extract your data into spreadsheets, or into JSON and CSV with the Beta API program. Having the ability to export the data to Word, Google Docs, PDF documents, and other formats would be great.
- Data selection process is a bit shallow: The Databoard page where you can select which data to consider and which to ignore does not offer many options. Having the possibility to preformat the data of interest, automatically include or avoid cards containing a particular string, or choose how to aggregate or split cards will be nice features to have.
Conclusion
In this article, we looked at what data you should scrape from a media article, why, and how to do it without writing a single line of code. This was possible thanks to Listly, a web scraping service that comes with a powerful, easy-to-use, and fast browser extension that empowers you with the ability to scrape any website. As shown, even though Listly comes with some minor pitfalls, my experience with it has been good overall.
Thanks for reading! I hope that you found this article helpful.
