
Python allows you to natively parse HTML and extract the data you need from it. Whether you are an experienced Python developer or just getting started, this step-by-step tutorial will teach you how to parse HTML with regex like a pro.
In this article, you will learn:
- How to get started with HTML Parsing using Regex in Python
- How parsing HTML with Regex works
- If you can use a regex to parse invalid HTML
Let’s dig into HTML parsing in Python!
An Introduction to HTML Parsing Using Regex
Find out the basics of regular expressions in Python for data parsing.
What Is a Regex?
A regex, short for “regular expression,” is a sequence of characters that defines a search pattern. Regular expressions can serve a variety of purposes, from data validation to searching and replacing text. In detail, regular expressions are used in data parsing to match, extract, and manipulate data from strings.
A regex consists of a pattern that specifies what the matching strings must look like. The pattern can include special characters and syntax that allows for complex pattern matching. For example, take a look at this regular expression pattern:<.+>(.*?)<\/.*>
This regex matches any HTML tag and the content between the opening and closing tag. Here is how it works:
-
<.+>: Matches an opening tag. -
(.*?): Matches any characters between the opening and closing tag. The parentheses define a group you can use to extract the text content wrapped between tags. -
<\/.*>: Matches the closing tag.
How to Use a Regex
Most programming languages support regular expressions natively. For example, Python comes with the re module. This provides features and operators to deal with regexes in Python.
To get started with regular expressions in Python, add this line on top of your .py script:
Then, you can define a regex with:
regex = re.compile(r'<.+>(.*?)<\/.*>', re.IGNORECASE | re.MULTILINE)
re.compile() compile a regular expression pattern into a regular expression object. Note that you can modify the behavior of the regex by specifying some flags value separated by the bitwise | operator. In the above example, the regex will be case-insensitive and also work on multi-line strings.
You can use the result of re.compile() with the re’s match(), search() and similar methods as shown here:
result = regex.match('<h1>Hello, World!</h1>') is not None # TrueNote that this is equivalent to:
result = re.match(regex, '<h1>Hello, World!</h1>') is not None # True
Testing a Regex Online
Defining the right regex is not easy and can become a trial-and-error process. This is especially true when you consider that different programming languages support different regex features. Also, the syntax of regular expressions can vary slightly from one programming language to another.
Before writing a regex in your code, you should use an online service like regex101 to build and test it. That service allows you to select a programming language and test the regex against some content in real-time. Also, it explains how the regex works and what groups it consists of.
See regex101 in action in this image:
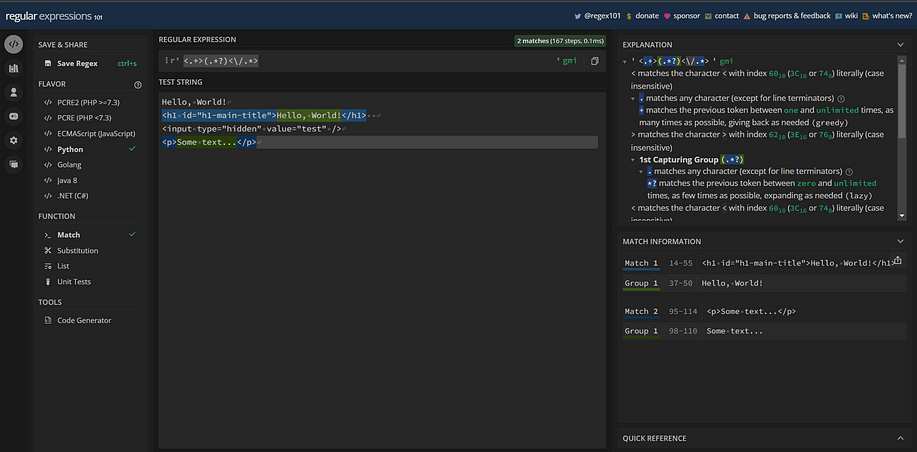
Notice that regex101 only matches the HTML lines of code that involve an opening and closing tag.
You know now what a regex is, how to use a regular expression in Python, and how to test them. You are ready to dig into parsing HTML content with regex in Python!
Parsing HTML With Regex
Regex-based HTML parsing is a powerful tool for extracting data from web pages. With the right regex, you can select any data from an HTML document. To get started, you first need to download the HTML content of your target page. You can achieve this with the url.lib Python HTTP client in a few lines:
import urllib.request
def get_html(url):
request = urllib.request.Request(
url=url,
# set a real User-Agent header
# to avoid 403 errors
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'
}
)
# perform the HTTP GET request and automatically freeing
# the resources allocated
with urllib.request.urlopen(request) as response:
# get the HTML content of the target web page
body = response.read()
return body.decode('utf-8')get_html() uses the urllib.request.urlopen() method to download the HTML document associated with the URL parameter. In detail, urlopen() performs an HTTP GET request to url and populates the response object. Then, get_html() calls the read() method on response to get access to the HTML content of the web page as a string. Finally, it returns the HTML as a UTF-8 decoded string.
Note that url.lib is part of the Python Standard Library. So, you can import it without installing any external dependencies. You can also achieve the same result with any other HTTP client, such as requests.
In this tutorial, you will see how to extract data from my personal website with regular expressions. This is what the target web page looks like:
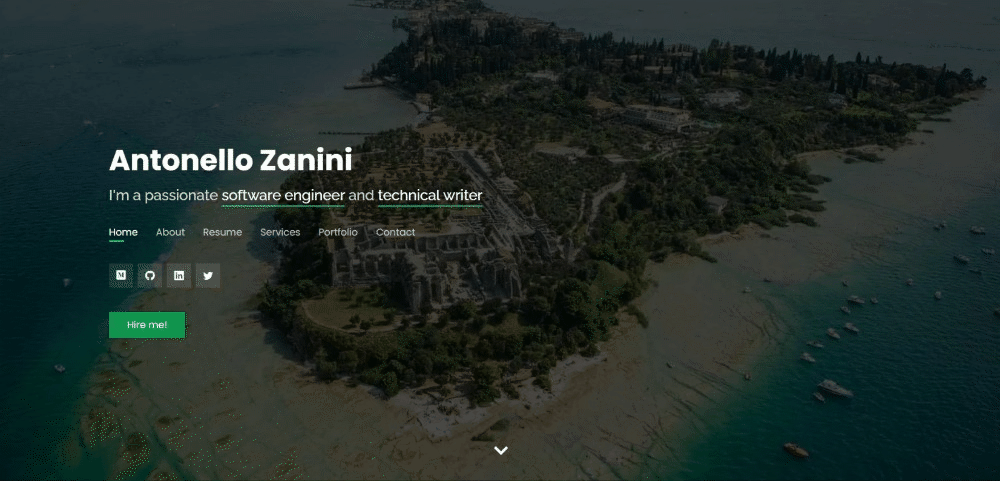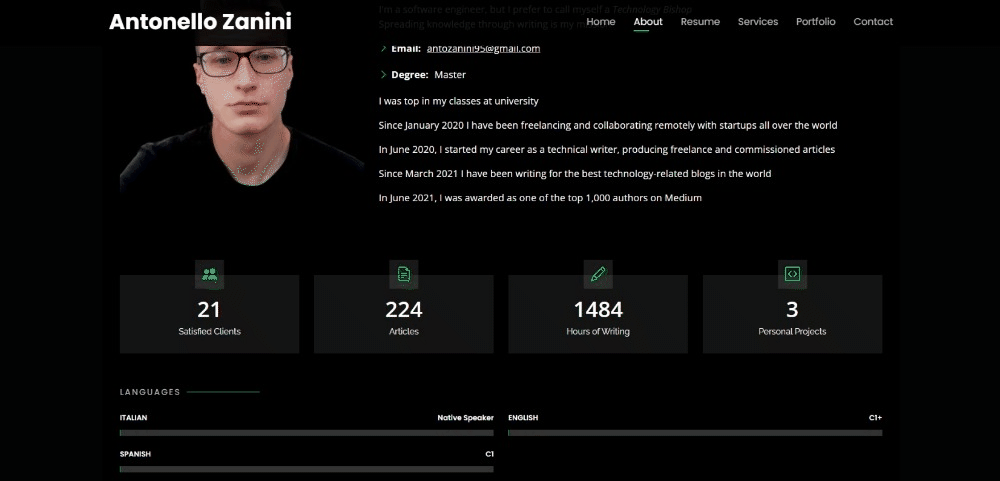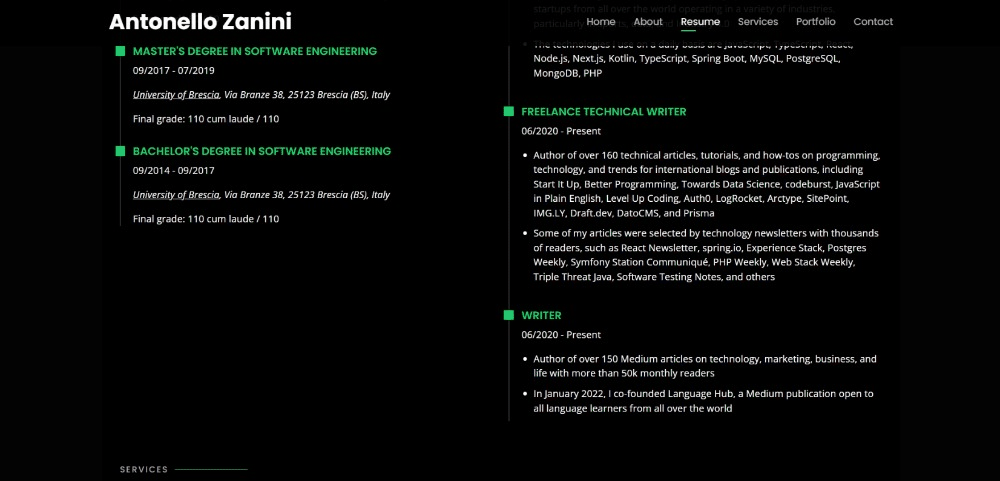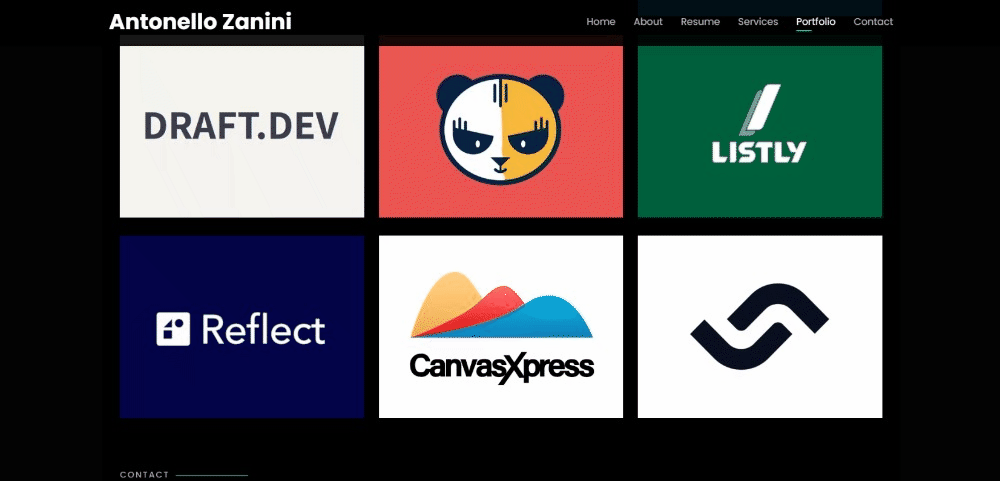
Use the get_html() function defined above to get the HTML content of the target site as a string with:
html = get_html("https://antonellozanini.com/")Let’s now understand how to parse HTML with regular expressions through some common examples!
Get Values From HTML Attributes
Web pages contain some of the most important data in the attributes of their HTML elements. For example, consider the values contained in the src, href, value, id, and class attributes. This is why being able to extract values from specific HTML attributes is so critical.
You can use a regex to extract the values from all attribute_name HTML attributes with:
def get_attribute_values(html, attribute_name):
# define the regex to get the value
# from the HTML attribute called "attribute_name"
regex_string = f'{attribute_name}="([^"]*)"'
# prepare the regex
regex = re.compile(rf'{regex_string}', re.IGNORECASE | re.MULTILINE)
# apply the regex to get all values
# from matching HTML attributes
values = re.findall(regex, html)
return valuesAssume you are interested in retrieving all ids contained in the antonellozanini.com. You can achieve that with:
ids = get_attribute_values(html, 'id')
Note that get_attribute_values() uses a Python f-string to programmatically build the target regex. When attribute_name contains the "id" string, regex_string will be initialized as:
id="([^"]*)"If you test this regex on regex101, you will see that its group matches the value contained in HTML id attributes:
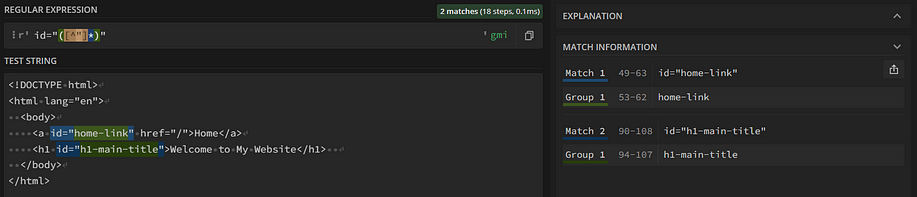
Then, get_attribute_values() applies the regex to the HTML content with re.find_all() method. When the regex contains only one group, find_all() returns a list of strings matching that group. So, ids will contain all id attribute values on the page:
[
'header',
'navbar',
# ...
'portfolio-filters',
'contact'
]Filtering out some specific elements from the HTML string makes parsing faster, easier, and more effective. For example, a <script> may contain some JavaScript code that could lead to undesired matches. Consider this HTML code:
<script> const id="test"; // JavaScript logic involving the "id" variable... </script>
When using get_attribute_values(html, 'id'), the resulting list will contain also the "test" value. This is because const id="test"; matches the id="([^"]*)" regex:
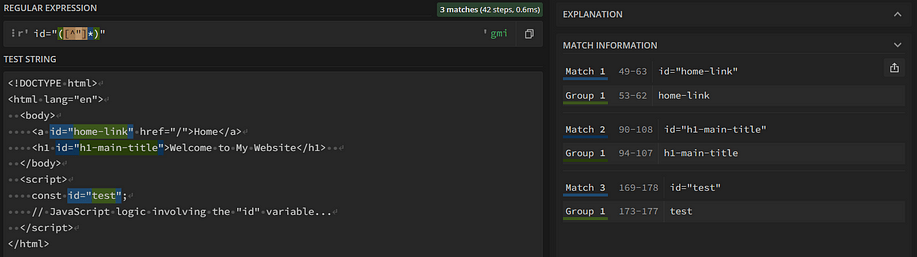
To avoid this type of problem, you can use a regex to filter out all tag_name HTML tags on the page as follows:
def remove_tag(html, tag_name):
new_html = html
regex_string = f'<{tag_name}[^>]*>\s*.*\s*<\/{tag_name}>'
regex = re.compile(rf'{regex_string}', re.IGNORECASE | re.MULTILINE)
# replace the matching patterns with an empty string
new_html = re.sub(regex, '', new_html)
return new_htmlNote that the re.sub() function returns the string obtained by replacing all regex occurrences with ''. In other terms, it removes all tag_name HTML elements and their content from the original HTML.
Similarly, you might be interested in removing all void HTML elements. If you are not familiar with them, a void tag is a self-closing tag that has no nested child nodes. These are some examples of void HTML tags:
<img src="image.jpg" alt="An image of a kitten" /> <input type="hidden" value="2firVCW8SsaJ4anH@ii#y" /> <br />
You can filter out all void tags in an HTML page using a regex with:
def remove_void_tags(html):
# list of self-closing void tags
# retrieved from
# https://developer.mozilla.org/en-US/docs/Glossary/Void_element
VOID_TAGS = [
"area", "base", "br", "col",
"embed", "hr", "img", "input",
"keygen", "link", "meta", "param",
"source", "track", "wbr"
]
new_html = html
for self_closing_tag in VOID_TAGS:
regex_string = f'<{self_closing_tag}[^>]+?\/?>'
regex = re.compile(rf'{regex_string}', re.IGNORECASE | re.MULTILINE)
new_html = re.sub(regex, '', new_html)
return new_htmlThis time, suppose html contains the code below:
<!DOCTYPE html>
<html lang="en">
<head>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Website</title>
<link rel="stylesheet" href="./style.css">
</head>
<body>
<h1>Welcome to My Website</h1>
<p>Some long<br />text</p>
<script>
console.log("Hello, World!");
</script>
</body>
</html>Call these two functions:
new_html = remove_tag(html, "script") new_html = remove_void_tags(new_html)
new_html will then contain:
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Website</title>
</head>
<body>
<h1>Welcome to My Website</h1>
<p>Some longtext</p>
</body>
</html>Great! The <script> and void tags have been removed successfully!
Extract Data From Text Nodes
Another crucial operation when it comes to HTML parsing is extracting text from HTML elements. You can achieve that through a regex in Python with:
def get_text(html, tag_name):
text_regex_string = f'<{tag_name}[^>]*>(.*?)<\/{tag_name}>'
text_regex = re.compile(rf'{text_regex_string}', re.IGNORECASE | re.MULTILINE)
text_nodes = re.findall(text_regex, html)
return text_nodesThis function extracts the text strings wrapped by each HTML tag_name instance.
My personal website contains several sections. Each of these has an h2 title that describes what the section contains. You can use get_text() to extract these titles as below:
titles = get_text(html, 'h2')
titles will contain:
[
'I'm a passionate <span>software engineer</span> and <span>technical writer</span>',
'About',
'Languages',
'Skills',
'Resume',
'Services',
'Portfolio',
'Contact'
]As you can notice from the first strings, get_text() does not return the text nodes contained in a specific tag but its inner HTML. So, get_text() works like a charm only when the selected nodes have no child elements. Let’s fix this!
Extend get_text() as shown here:
def get_text(html, tag_name):
text_regex_string = f'<{tag_name}[^>]*>(.*?)<\/{tag_name}>'
text_regex = re.compile(rf'{text_regex_string}', re.IGNORECASE | re.MULTILINE)
inner_html_nodes = re.findall(text_regex, html)
# the proper list of text nodes
text_nodes = []
for inner_html_node in inner_html_nodes:
# clean the inner HTML node from
# void tags
text_node = remove_void_tags(inner_html_node)
# remove all HTML opening tag strings
opening_tag_regex_string = f'<[^>]*>'
opening_tag_regex = re.compile(rf'{opening_tag_regex_string}', re.IGNORECASE | re.MULTILINE)
text_node = re.sub(opening_tag_regex, ' ', text_node)
# remove all HTML opening tag strings
closing_tag_regex_string = f'<\/[^>]*>'
closing_tag_regex = re.compile(rf'{closing_tag_regex_string}', re.IGNORECASE | re.MULTILINE)
text_node = re.sub(closing_tag_regex, ' ', text_node)
text_nodes.append(text_node)
return text_nodesThe function now takes care of removing all HTML raw code from the wrapped strings.
Run the following line of code again:
titles = get_text(html, 'h2')
This time, you will get:
[
'I'm a passionate software engineer and technical writer',
'About',
'Languages',
'Skills',
'Resume',
'Services',
'Portfolio',
'Contact'
]Fantastic! The first three strings now involve only simple text and no longer contain HTML code.
Extract Messages From HTML Comments
HTML comments contain useful information written by developers. These provide insight into what a particular section of code does or the problems the developer faced with it. Use Python to get HTML comment messages through a regex with:
def get_comments(html):
regex_string = '<!--\s*(.*?)\s*-->'
regex = re.compile(rf'{regex_string}', re.IGNORECASE | re.MULTILINE)
comments = re.findall(regex, html)
return commentsSuppose html contains this code:
<!DOCTYPE html>
<html lang="en">
<head>
<!-- Print the text -->
<title>My Website</title>
</head>
<body>
<h1>Welcome to My Website</h1>
</body>
</html>Call get_comments() with:
comments = get_comments(html)
comments will then store:
[
'Set the title in the browser tab',
'Page main title'
]Well done! You can now retrieve the messages left by developers in the HTML code!
Get All Links on the Page
Now that you know how to parse HTML with regular expressions in different scenarios, it is time to challenge yourself with a more complex goal. Suppose you are interested in getting all the URLs contained in the <a> links on a page.
The first approach you may take is:
get_attribute_values(html, 'href')
Yet, this function is not bulletproof. Assume that your target page contains the following HTML code:
<!DOCTYPE html>
<html>
<head>
<title>My page</title>
</head>
<body>
<a id="home-link" href="https://antonellozanini.com">Home</a>
<button onclick="updateLink()">Change Link Href</button>
<script>
function updateLink() {
const link=document.getElementById("home-link");
link.href="https://antonellozanini.com/#services";
}
</script>
</body>
</html>get_attribute_values(html, 'href') will detect both "https://antonellozanini.com" and "https://antonellozanini.com/#services". To avoid this behavior, you may think about filtering out <script> elements with:
remove_tag(html, 'script')
Again, this is not enough. For example, consider the HTML code below:
<button onclick='document.getElementById("home-link").href="https://antonellozanini.com/#services"'>Change Link Href</button>This will fool the get_attribute_values(html, 'href') method just like before.
Since your goal is to get the value of a specific attribute of a particular HTML tag, you can:
- Use a regex to retrieve the HTML content contained in the instances of the target tag.
- Take advantage of a regular expression to extract the value of the desired HTML attribute from each of them.
Implement this logic with:
def get_attribute_from_tag(html, tag_name, attribute_name):
# get the inner HTML content associated with
# the isntances of the tag of interest
tag_regex_string = f'<{tag_name}[^>]*>.*?<\/{tag_name}>'
tag_regex = re.compile(rf'{tag_regex_string}', re.IGNORECASE | re.MULTILINE)
tags = re.findall(tag_regex, html)
values = []
for tag in tags:
attribute_values = get_attribute_values(tag, attribute_name)
# if the HTML code contained in tag of interest
# contains the desired attribute
if len(attribute_values) > 0:
values.append(attribute_values[0])
return valuesTo get all link URLs on the page, call:
get_attribute_from_tag(html, 'href', 'a')
Congrats! You just learned how to use Python regex to parse HTML in both basic and complex scenarios.
In the examples above, you had the opportunity to deal with some typical issues of regex. So, you might now be wondering if regexes are really the best and most general-purpose solution to HTML parsing. Let’s dig into this!
Can You Parse Invalid HTML With a Regex?
Modern browsers are advanced and flexible enough to still render invalid, broken, or non-standard HTML correctly. If a web page contains HTML errors, the browser will still try to render it as naturally and consistently as possible. Thus, web developers tend to ignore HTML standards and might write broken HTML without even realizing it.
As a result, many web pages contain invalid or arbitrary HTML. The problem is that HTML parsing using regex relies on the assumption that the string to test against contains correct HTML in a standard format.
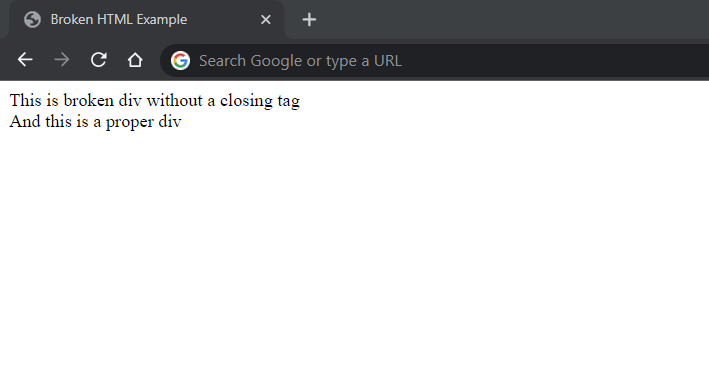
Take a look at this HTML page:
<!DOCTYPE html>
<html>
<head>
<title>Broken HTML Example</title>
</head>
<body>
<div>This is a broken div without a closing tag
<div>And this is a proper div</div>
</body>
</html>The first <div> does not get closed. Yet, Chrome manages to render the page correctly:
Now, try to extract the text from the two <div>s with:
get_text(html, 'div')
get_text() will extract the text only from the proper <div> and return:
[
'And this is a proper div'
]You could introduce custom logic to process this particular case, but there are several other scenarios where regexes can fail. This is why you should prefer a general-purpose Python HTML parser such as Beautiful Soup.
Conclusion
Python allows you to parse HTML content with regexes. These are string patterns you can use to select and extract data from HTML documents. Regexes are powerful, and here you saw the most common examples of how to use a regex to parse HTML content. At the same time, you also understood the limitations of that approach.
Thanks for reading! I hope you found this article helpful.
