
Dividing a codebase into different levels reduces the effort required for maintenance since each level can be managed independently of others. This simplifies the way the software infrastructure can be controlled. Plus, when a software architecture is split into multiple layers, the required changes are localized, simpler, and less extensive than they would otherwise be.
Designing effective multi-layered architecture is a common way to avoid unnecessary problems and write high-quality code.
How can this be achieved with Spring Boot and Kotlin?
Application Architecture
The project structure must represent the designed multi-layered architecture. In particular, each layer should be enclosed in a specific package. Each of them should have the same name as the layer itself. In this way, finding a class becomes very easy and intuitive. At the same time, there will be no doubts about where to place a new class. The project structure should look like this:
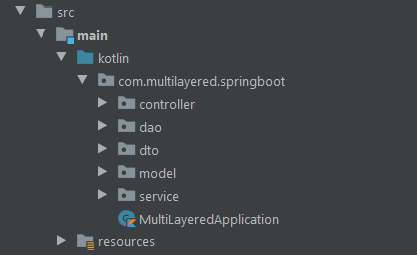
Which layers do good multi-layered architectures consist of?
Model Layer
“Entities in JPA are nothing but POJOs representing data that can be persisted to the database. An entity represents a table stored in a database. Every instance of an entity represents a row in the table.” — Defining JPA Entities
Entities can also be seen as the application model, and they should be placed inside the model package.
Defining JPA Entities in Kotlin can be a bit tricky, so following this guide is greatly recommended.
In order to do define a proper model, each entity class has to be marked with @Entity annotation.
@Entity
@Table(name = "author")
open class Author {
@get:Id
@get:GeneratedValue(strategy = GenerationType.IDENTITY, generator = "native")
@get:Column(name = "id", unique = true, nullable = false)
open var id: Int? = null
@get:Basic
@get:Column(name = "name", nullable = false, length = 50)
open var name: String? = null
@get:Basic
@get:Column(name = "surname", nullable = false, length = 50)
open var surname: String? = null
@get:Basic
@get:Column(name = "birthDate", nullable = true)
@get:Temporal(TemporalType.DATE)
open var birthDate: Date? = null
@get:ManyToMany(fetch = FetchType.LAZY)
@get:JoinTable(
name = "author_book",
joinColumns = [JoinColumn(name = "author_id")],
inverseJoinColumns = [JoinColumn(name = "book_id")]
)
open var books: MutableSet<Book> = HashSet()
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (javaClass != other?.javaClass) return false
other as Author
if (id != other.id) return false
return true
}
override fun hashCode(): Int {
if (id == null)
return 0
return id!!
}
}@Entity
@Table(name = "book")
open class Book {
@get:Id
@get:GeneratedValue(strategy = GenerationType.IDENTITY, generator = "native")
@get:Column(name = "id", unique = true, nullable = false)
open var id: Int? = null
@get:Basic
@get:Column(name = "title", nullable = false, length = 50)
open var title: String? = null
@get:Basic
@get:Column(name = "releaseDate", nullable = true)
@get:Temporal(TemporalType.DATE)
open var releaseDate: Date? = null
@get:ManyToMany(
fetch = FetchType.LAZY,
mappedBy = "books"
)
open var authors: MutableSet<Author> = HashSet()
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (javaClass != other?.javaClass) return false
other as Book
if (id != other.id) return false
return true
}
override fun hashCode(): Int {
if (id == null)
return 0
return id!!
}
}DAO Layer
“DAO stands for Data Access Object. Usually, the DAO class is responsible for two concepts. Encapsulating the details of the persistence layer and provide a CRUD interface for a single entity.” — A Controller, Service and DAO Example with Spring Boot and JSF
DAOs are supported by Spring to make it easy to work with different data access technologies like JDBC, Hibernate, JPA, or JDO consistently. Switching between the aforementioned persistence technologies becomes easy thanks to the DAOs layer. In order to code without worrying about catching exceptions that are specific to each technology each DAO class has to be marked with @Repository annotation.
DAOs should be placed in the dao package.
Each entity class should have a respective DAO.
I recommend reading this article to understand how to build JPA robust criteria queries using JPA Metamodel.
To avoid boilerplate code, generics can be used as follows:
@Repository
class AuthorDao : EntityDao<Author, Int>() {
override var entity : Class<Author>? = Author::class.java
fun findByName(
name : String
) : List<Author> {
val criteriaBuilder = getCriteriaBuilder()
val criteriaQuery = getCriteriaQuery()
val root = criteriaQuery.from(entity)
val query =
criteriaQuery
.select(root)
.where(
criteriaBuilder.like(root.get(Author_.name), "%$name%")
)
return getQuery(query).resultList
}
}@Repository
abstract class EntityDao<T, KEY : Serializable?> {
@PersistenceContext
protected lateinit var entityManager: EntityManager
protected var entity : Class<T>? = null
fun findByKey(key: KEY): Optional<T> {
return Optional.of(entityManager.find(entity, key))
}
fun findAll(): List<T> {
val criteriaQuery = getCriteriaQuery()
val root = criteriaQuery.from(entity)
val resultQuery = getQuery(criteriaQuery.select(root))
return resultQuery.resultList
}
fun create(entity: T) : T {
entityManager.persist(entity)
return entity
}
fun update(entity: T) : T {
return entityManager.merge(entity)
}
fun delete(entity: T) : T {
entityManager.remove(entity)
return entity
}
protected fun getCriteriaBuilder(): CriteriaBuilder {
return entityManager.criteriaBuilder
}
protected fun getCriteriaQuery(): CriteriaQuery<T> {
return entityManager.criteriaBuilder.createQuery(entity)
}
protected fun getQuery(criteriaQuery : CriteriaQuery<T>): TypedQuery<T> {
return entityManager.createQuery(criteriaQuery)
}
}Service Layer
“The DAO layer’s main goal is to handle the details of the persistence mechanism. While the service layer stands on top of it to handle business requirements.” — A Controller, Service and DAO Example with Spring Boot and JSF
Service classes should be defined under the service package and this layer is responsible for (but not limited to):
- Encapsulating the business logic;
- Defining where the transactions begin and end;
- Centralizing data access.
In order to define a proper service, each service class should be marked with @Service annotation.
Is a Layer Between Controllers and DAOs Really Required?
Let’s suppose to have a single back-end system that provides data to a mobile application and a web application respectively. The former might need data in a different representation than the latter. A solution is to define two different APIs. One for the mobile application and the other for the web application. This works but leads to possible code duplication. In fact, the two APIs may perform the same operations.
Defining a layer between DAOs and Controllers increment the level of decoupling and make each controller function easier to manage and read. The service layer can also be used to define authorization policies that each operation may require. In conclusion, the service layer is where to place any business logic operation that one or more controllers need, except for (de)serialization.
@Service
class AuthorService : CustomService() {
fun getByKey(key : Int) : Author {
return authorDao.findByKey(key).get()
}
fun getByName(name : String) : List<Author> {
return authorDao.findByName(name)
}
fun getAll() : List<Author> {
return authorDao.findAll()
}
}@Transactional(readOnly = true)
abstract class CustomService {
@Autowired
protected lateinit var authorDao: AuthorDao
@Autowired
protected lateinit var bookDao: BookDao
}Controller Layer
The controller layer is in charge of handling a request from the moment when it is intercepted to the generation of the response and its transmission. What a controller does is to call one or more service layer functions. It also manages the deserialization of the request and the serialization of the response, through the DTO layer.
Avoiding passing DTOs as parameters to the service layer (or to receive them from it) allows the system to be highly decoupled and keeps the service layer completely independent of data representation. To achieve this defining a new layer may be necessary, as described in the Extras section.
Controllers should be placed in the controller package, and each controller class has to be marked with @RestController (or @Controller) annotation.
Best practices recommend declaring a version for each function, then each API. In fact, this layer should be kept versioned to support multiple versions of an API at the same time.
@RestController
@RequestMapping("/authors")
class AuthorController : CustomController() {
@Autowired
lateinit var authorMapper: AuthorMapper
@GetMapping("v1/")
fun getAll() : ResponseEntity<List<AuthorDto>> {
return ResponseEntity(
authorMapper.authorsToAuthorDtos(
authorService.getAll()
), HttpStatus.OK)
}
@GetMapping("v1/special/{id}")
fun getSpecial(@PathVariable(value = "id") id: Int) : ResponseEntity<SpecialAuthorDto> {
return ResponseEntity(
authorMapper.authorToSpecialAuthorDto(
authorService.getByKey(id)
), HttpStatus.OK)
}
@GetMapping("v1/{id}")
fun get(@PathVariable(value = "id") id: Int) : ResponseEntity<AuthorDto> {
return ResponseEntity(
authorMapper.authorToAuthorDto(
authorService.getByKey(id)
), HttpStatus.OK)
}
@GetMapping("v1/find")
fun findByName(
@RequestParam(value = "name", required = true) @NotEmpty @NotBlank name: String
) : ResponseEntity<List<AuthorDto>> {
return ResponseEntity(
authorMapper.authorsToAuthorDtos(
authorService.getByName(name)
), HttpStatus.OK)
}
}@Validated
@Transactional(readOnly = true)
abstract class CustomController {
@Autowired
protected lateinit var authorService: AuthorService
@Autowired
protected lateinit var bookService: BookService
}DTO Layer / (De)Serialization Layer
“DTO or Data Transfer Objects is an object that carries data between processes. The motivation for its use is that communication between processes is usually done resorting to remote interfaces (e.g., web services), where each call is an expensive operation”
Data Transfer Objects are used to decouple data representation to (and not only) model objects. DTOs can be employed to (de)serialize data objects in several ways.
DTOs should be placed in the dto package, and since they usually require one or more mappers, a mapper sub-package may be useful as well.
Multi-layered applications often require you to define mapping logic between different object models (e.g., entities and DTOs). Writing such mapping code is a tedious, error-prone task, and involves boilerplate code. So, the following guide is highly recommended:
class AuthorDto {
@JsonProperty("id")
var id: Int? = null
@JsonProperty("name")
var name: String? = null
@JsonProperty("surname")
var surname: String? = null
@JsonProperty("birthDate")
@JsonFormat(pattern = "MM/dd/yyyy")
var birthDate: Date? = null
@JsonProperty("books")
var books: List<BookDto> = ArrayList()
}class BookDto {
@JsonProperty("id")
var id: Int? = null
@JsonProperty("title")
var title: String? = null
@JsonProperty("releaseDate")
@JsonFormat(pattern = "MM/dd/yyyy")
var releaseDate: Date? = null
}Extras
Data Layer
In order to achieve the highest possible level of decoupling from this multi-layered architecture, a new layer may be required. Passing data from controllers to services (and vice versa) as well as from services to DAOs (and vice versa) may require the use of specific data structures. These data transportation classes should be placed in another layer, which could be called data.
In complex architectures, this layer is strongly recommended since it standardizes the way that functions of each of the aforementioned layers should be accessed.
API Layer
The following article explains how to build an API layer to add to this multi-layered architecture: Avoiding Code Duplication by Adding an API Layer in Spring Boot.
Error-Handling Layer
The following article explains how to build a custom error-handling layer to add to this multi-layered architecture: Environment-Based Error Handling With Spring Boot and Kotlin.
Having an API To List All Endpoints Exposed
As your project grows, you can easily lose sight of what is going on or what is currently deployed. This is exactly why you should protect yourself by adding some monitoring tools, and having an API to list all endpoints exposed can save your day: Building an API To List All Endpoints Exposed by Spring Boot.
Returning CSV Content Instead of JSON
Avoiding conversion overhead by returning CSV data directly from your APIs might be useful, especially when dealing with CRMs or data science. The following article explains how to achieve this: Returning CSV Content From an API in Spring Boot.
Conclusion
The source code of his article can be found on my GitHub repository.
I hope this helps someone design a multi-layered architecture for RESTful web services with Spring Boot and Kotlin! Let me know if you have any comments or suggestions.
